
The rise of artificial intelligence (AI) has ushered in an era of unprecedented technological advancement, with AI models capable of performing tasks once thought to be exclusive to humans. At the heart of this revolution lies the concept of training data, the fuel that powers AI models.
However, as AI models become increasingly sophisticated, questions arise about the ethical implications of using user input for training. This raises concerns about data privacy, transparency, and the potential for unintended consequences.
This exploration delves into the complex relationship between user input and AI model training, examining the ethical considerations surrounding data collection, usage, and the need for transparency and user control. By understanding the intricate dynamics at play, we can strive to develop and deploy AI systems that are both powerful and responsible, safeguarding user privacy while fostering innovation.
Data Privacy and User Input

The relationship between user input and data privacy is a crucial aspect of AI model development and deployment. User input, which can range from text prompts to images and audio recordings, is often used to train AI models, enhancing their performance and capabilities.
However, this practice raises concerns about data privacy and the potential misuse of personal information.
User Input as Training Data
User input serves as valuable training data for AI models, enabling them to learn patterns and generate more relevant outputs. For example, user input in the form of text prompts can be used to train language models, allowing them to understand and generate human-like text.
Similarly, images uploaded by users can be used to train image recognition models, enabling them to identify objects and scenes with greater accuracy.
- Text Prompts:User input in the form of text prompts can be used to train language models, allowing them to understand and generate human-like text. This can be seen in chatbots, where user prompts are used to train the chatbot to respond in a natural and engaging manner.
- Images:Images uploaded by users can be used to train image recognition models, enabling them to identify objects and scenes with greater accuracy. For instance, social media platforms often use user-uploaded images to train their image recognition models, allowing them to identify faces, objects, and scenes in user-generated content.
- Audio Recordings:Audio recordings, such as voice commands or conversations, can be used to train speech recognition models. This allows AI systems to understand and transcribe spoken language, enabling applications like voice assistants and dictation software.
AI Model Training Data
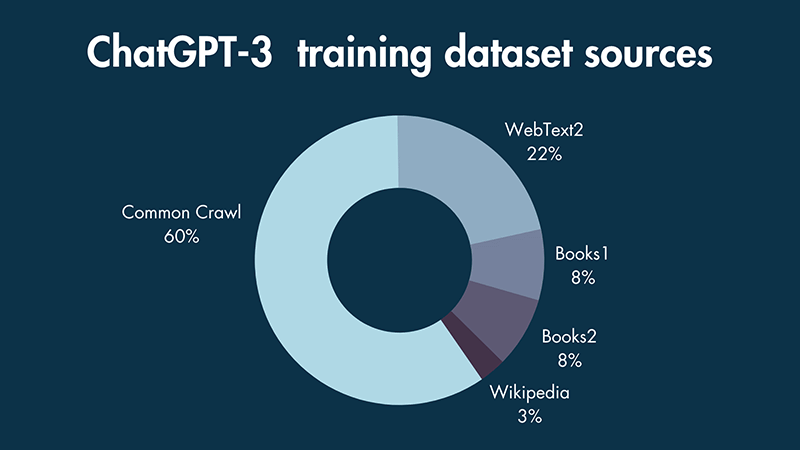
AI models, including Kami, are trained on massive datasets of text and code. These datasets are crucial for the models to learn patterns, understand language, and generate responses. The sources of this training data are diverse, each carrying unique ethical implications and considerations.
Sources of Training Data
The data used to train AI models can be categorized into several sources, each with its own characteristics and potential impact:
- Publicly Available Text and Code:This includes books, articles, websites, code repositories, and other publicly accessible content. While readily available, this data may contain biases and inaccuracies present in the original sources.
- Proprietary Datasets:Companies and organizations often possess large datasets specific to their domains. These datasets can provide valuable insights, but their use raises concerns about privacy and potential misuse.
- User-Generated Content:Social media posts, online forums, and other platforms generate vast amounts of user-generated content. This data can offer a diverse range of perspectives, but it also presents risks related to misinformation, hate speech, and other harmful content.
- Synthetic Data:Generated using algorithms, synthetic data aims to replicate real-world data while mitigating privacy concerns. However, it’s crucial to ensure the synthetic data accurately reflects the real world and avoids introducing biases.
Ethical Implications of Training Data
The ethical implications of using different types of training data are significant and require careful consideration:
- Bias and Discrimination:Training data often reflects existing biases and prejudices present in society. If these biases are not addressed, AI models can perpetuate and even amplify them, leading to discriminatory outcomes.
- Privacy Concerns:The use of personal data in training datasets raises concerns about privacy violations. It’s essential to ensure that data is anonymized or used with appropriate consent and safeguards.
- Misinformation and Manipulation:Training models on unreliable or manipulated data can lead to the generation of false or misleading information. This poses risks for spreading misinformation and influencing public opinion.
- Fairness and Transparency:The use of training data should be transparent and accountable. It’s crucial to understand the sources and characteristics of the data used to train models and to mitigate potential biases and risks.
Importance of Data Diversity and Representation
Data diversity and representation are essential for building fair and unbiased AI models:
“Diversity in training data is crucial for mitigating bias and promoting fairness in AI models.”
- Reducing Bias:Training models on diverse datasets helps reduce biases by exposing them to a wider range of perspectives and experiences.
- Improving Accuracy:Diverse data improves the accuracy and generalizability of AI models by enabling them to perform better across different contexts and populations.
- Ensuring Fairness:Representation of diverse groups in training data is essential for ensuring that AI models are fair and equitable in their outcomes.
Transparency and Accountability
Transparency and accountability are crucial aspects of responsible AI development. They ensure that AI systems are developed and used ethically, fairly, and with a clear understanding of their capabilities and limitations. These principles foster trust and allow for informed decision-making regarding AI’s impact on society.
Transparency in AI Model Training
Transparency in AI model training involves providing insights into the model’s development process, including the data used, the algorithms employed, and the model’s decision-making logic. This transparency allows stakeholders to understand the model’s strengths and weaknesses, identify potential biases, and evaluate its suitability for specific applications.
- Data Transparency:Disclosing the sources, characteristics, and potential biases of the training data used to develop the AI model. This information helps understand the model’s potential limitations and biases. For example, a language model trained on a dataset predominantly consisting of news articles might exhibit biases reflecting the perspectives presented in those articles.
- Algorithm Transparency:Explaining the algorithms used in the AI model, including their design, parameters, and how they process data. This information allows for understanding the model’s decision-making process and identifying potential vulnerabilities or biases. For example, a model using a specific machine learning algorithm might be more prone to certain types of errors than another algorithm.
- Model Explainability:Providing insights into the model’s decision-making process, enabling users to understand why the model makes specific predictions or recommendations. This can be achieved through techniques like feature attribution, which identifies the input features most influential in the model’s decision. For example, a loan approval model could use feature attribution to highlight the factors contributing to the approval or rejection of a loan application.
- Model Performance Evaluation:Publishing metrics and evaluation results demonstrating the model’s performance on various tasks and datasets. This information helps assess the model’s reliability and accuracy, identifying potential areas for improvement. For example, evaluating a chatbot’s performance on different conversational scenarios can reveal its strengths and weaknesses in handling various user interactions.
Measures for Transparency in AI Model Training
Various measures can be implemented to enhance transparency in AI model training. These measures aim to provide stakeholders with access to relevant information and empower them to understand and evaluate AI systems effectively.
- Documentation and Reporting:Maintaining comprehensive documentation detailing the model’s development process, including the data used, algorithms employed, performance metrics, and ethical considerations. This documentation should be readily accessible to relevant stakeholders.
- Data Provenance Tracking:Tracking the origin and transformation of data throughout the model training process, allowing for tracing data lineage and identifying potential biases or errors. This ensures accountability for data integrity and model accuracy.
- Model Auditing and Verification:Conducting independent audits and verifications of AI models to assess their performance, identify potential biases, and ensure compliance with ethical guidelines. This involves evaluating the model’s behavior on various datasets and scenarios.
- Open-Source Development:Making AI models and their training data publicly available, allowing for independent research, scrutiny, and improvement. This promotes collaboration and transparency in AI development, fostering a more open and accountable ecosystem.
- Public Engagement and Education:Engaging with the public to educate them about AI systems, their capabilities, and limitations. This fosters informed public discourse and promotes responsible AI development and use.
Data Anonymization and Ethical Data Handling
Data anonymization plays a crucial role in protecting user privacy and ensuring ethical data handling in AI development. It involves transforming data to remove personally identifiable information while preserving its utility for model training.
- Data Anonymization:Techniques like data aggregation, generalization, and suppression are used to remove or obfuscate personally identifiable information from datasets. This ensures that the data used for training AI models does not compromise user privacy.
- Ethical Data Handling:Implementing practices to ensure that data is collected, used, and stored ethically, respecting user privacy and adhering to relevant regulations. This involves obtaining informed consent, minimizing data collection, and implementing robust data security measures.
Flowchart: Data Anonymization and Ethical Data Handling
[Insert Flowchart Here]The flowchart illustrates the process of data anonymization and ethical data handling in AI development. It highlights key steps, including data collection, anonymization, model training, and data storage, emphasizing the importance of ethical considerations throughout the process.
User Consent and Control
The use of user data for AI model training raises crucial questions about user consent and control. While AI models can benefit from vast amounts of data, it’s essential to ensure that data collection and usage practices are transparent and respect user privacy.
The principle of informed consent is paramount in data privacy. Users should be aware of how their data is being collected, used, and potentially shared, and they should have the opportunity to provide explicit consent for these practices.
Methods for Providing User Control
Providing users with meaningful control over their data is crucial. This can be achieved through various methods:
- Data Minimization:Only collect the data that is absolutely necessary for the intended purpose. This reduces the amount of data that could be misused or compromised.
- Data Access and Deletion:Users should be able to access, correct, and delete their personal data. This allows them to manage their information and ensure its accuracy.
- Data Portability:Users should be able to easily transfer their data to other services. This empowers them to switch providers without losing their data.
- Data Use Controls:Users should be able to specify how their data can be used. For example, they might choose to opt out of having their data used for training AI models.
Importance of Clear and Accessible Information
Clear and accessible information about data privacy policies is essential for informed consent. This information should be readily available and easy to understand, using plain language and avoiding technical jargon.
- Transparency:Clearly explain the purpose of data collection, how the data will be used, and with whom it may be shared.
- Accessibility:Make data privacy policies readily available and easy to find.
- Concise and Clear Language:Avoid complex legal terms and use simple, understandable language.
Potential Risks and Mitigation Strategies
The use of user data for AI model training, while potentially beneficial, raises concerns about privacy and security. Understanding these risks and implementing appropriate mitigation strategies is crucial for responsible AI development.
Data Privacy and Security Risks
The potential misuse of user data in AI training poses significant risks. This includes the possibility of sensitive information being exposed, leading to privacy breaches, discrimination, or reputational damage.
- Data breaches:Unauthorized access to training data could lead to the exposure of sensitive information, potentially affecting individuals’ privacy and security.
- Discrimination:Biased training data can lead to AI models that perpetuate and even amplify existing societal biases, resulting in unfair or discriminatory outcomes.
- Reputational damage:The misuse of user data for AI training can damage the reputation of individuals and organizations involved.
Mitigation Strategies
Addressing these risks requires a multi-pronged approach involving data anonymization, differential privacy, and ethical guidelines.
Data Anonymization
Data anonymization involves removing or altering personally identifiable information from datasets to protect user privacy.
- Data masking:Replacing sensitive information with random or synthetic values.
- Data aggregation:Combining data from multiple individuals to create aggregate statistics, concealing individual-level information.
- Data generalization:Replacing specific values with broader categories, such as replacing exact age with age ranges.
Differential Privacy
Differential privacy is a technique that adds noise to data during analysis, making it difficult to identify individual contributions while still allowing for accurate statistical inferences.
- Noise injection:Adding random noise to data values, obscuring individual information while preserving overall data patterns.
- Privacy budget allocation:Limiting the amount of information that can be extracted from the data, ensuring a balance between privacy and utility.
Ethical Guidelines and Best Practices
Ethical guidelines and best practices are essential for responsible AI development. These guidelines should address issues such as data ownership, transparency, accountability, and user consent.
- Data ownership and control:Users should have control over their data and be informed about how it is being used.
- Transparency and accountability:AI models should be developed and deployed transparently, with clear accountability mechanisms in place.
- User consent:Users should be explicitly informed about the use of their data for AI training and given the option to opt out.
Last Word
The ethical use of user input in AI training is a critical aspect of responsible AI development. By prioritizing transparency, user consent, and data anonymization, we can mitigate risks and foster trust in AI systems. As AI continues to evolve, it is imperative that we navigate this complex landscape with a strong commitment to ethical principles, ensuring that AI serves humanity while safeguarding individual rights.
FAQ Summary
What is the difference between data anonymization and differential privacy?
Data anonymization aims to remove identifying information from data, making it difficult to link individuals to specific data points. Differential privacy, on the other hand, adds random noise to data, making it impossible to identify individual contributions while still preserving the overall statistical properties of the data.
How can users ensure their data is not used for AI training without their consent?
Users can exercise their right to data privacy by opting out of data collection or usage for AI training. They should carefully review privacy policies and seek clear and accessible information about how their data is used. Some platforms may offer settings to control data sharing for AI purposes.
What are some examples of ethical guidelines for responsible AI development?
Several organizations, including the IEEE, ACM, and the Partnership on AI, have developed ethical guidelines for responsible AI development. These guidelines emphasize principles such as fairness, transparency, accountability, and user privacy.